“I enjoyed writing. Perhaps it was because I hardly heard the sound of my own voice. My written words were my voice, speaking, singing, … I was there on the page” – Jenny Moss
We have a natural desire for expressive writing to hear the voice deep inside ourselves in difficult times. Although previous studies have proven therapeutic effects of expressive writing, most of them studied the activity in controlled labs where the writing was guided by a researcher. We think that therapeutic expressive writing happens spontaneously in the real world as well. We focus on spontaneous expressive writing on CaringBridge, an online platform for people to write and share their or their beloved ones’ health journeys and get support. Our goal was developing a computational model to infer whether a post does or does not contain expressive writing in order to help people get more benefit from using online health communities like CaringBridge.
One major challenge we encountered to achieve this goal is that there is no past data on therapeutic expressive writing in the wild. To address this challenge we thought about how we could adapt expressive writing data that was collected in the lab. We looked at 47 past lab studies and what they could tell us about expressive writing. Turns out that the writing that was counted as “expressive” in these studies, shared some common characteristics: it used emotion and cognitive words a lot more than the writing that was not “expressive”. We used a clever statistical model (more details in the paper) to look at each CaringBridge post and tell us how much it matched those characteristics. The research team also looked at 200 posts ourselves to see how often our model would come to the same conclusion as the research team as to whether a blog post constituted “expressive writing”. We agreed about 67% of the time, so there’s obviously a lot of room for improvement (we assume that humans are generally right and that the algorithm needs to improve how well it recognizes these posts).
Despite the limitations of the model, it provides the first ever opportunity to understand how often expressive writing may occur in the wild. We applied our model to the dataset of 13 million CaringBridge journal posts and inferred 22% were expressive and 78% were not expressive. This provides evidence for spontaneous expressive writing in the wild.
To sum up, our paper has three contributions. First, it demonstrates a way to use aggregated empirical data. In cases where no data are available, we could use common characteristics reported in past studies to study the group we are interested in, as we did in the paper. Second, it provides a baseline model to infer expressive writing and to be improved upon. Future research could use more sophisticated features and models by constructing a gold standard dataset or transferring knowledge from a related task that has already been learned. Third, it identifies expressive writing as a potential measure for online health communities. How much an individual engages with spontaneous expressive writing not only reveals their current writing practices, but also reveals the difficult times they are going through. Online health communities can then target their messaging by sending emotional support to those in difficult times and providing writing tips to those who are less expressive so that people can gain the most benefits from their writing.
Wikipedia is the online encyclopedia that anyone can edit. However, you probably didn’t know that “bots” (software tools) also edit Wikipedia! Human editors (“Wikipedians”) work together with bots to keep Wikipedia up to date. However, bots’ edits can conflict with each other; some have even written about bot editing wars “raging on Wikipedia’s pages”! But is this true? If it were really happening, bot conflict would be a big deal: bots automatically enforce the encylopedia’s rules, so identifying bot conflict can help Wikipedians refine editing processes. However, previous researchers have used overly-simple approaches to quantify conflict, ignoring the context of specific bot edits. To understand what bots were actually doing, we conducted a qualitative analysis of the context in which bots make edits. We found no evidence of bot conflict, though we did find some malfunctioning bots.
We are Abby Newcomb (St. Olaf College) and Sokona Mangane (Bates College), participants in the University of Minnesota’s 2021 Computer Science REU. In this blog post, we’re going to talk about the editing patterns of four bots on Wikipedia: AvicBot, Cyberbot I, RonBot, and AnomieBOT. Using these bots as a case study, we will show that what may appear to be conflict is routine and expected when examined in context.
How do bots edit Wikipedia?
Bots are automated or semi-automated software agents programmed to carry out various tasks. According to the Wikipedia page Wikipedia:Bots, bots carry out tasks that are “repetitive and mundane” in order to maintain the encyclopedia. Bots adhere to the Wikipedia bot policy and are approved by human editors in the Bot Approvals Group before they are allowed to edit any Wikipedia pages. Most bots do not make edits on actual encyclopedia articles, but take care of housekeeping tasks necessary to keep the encyclopedia running.
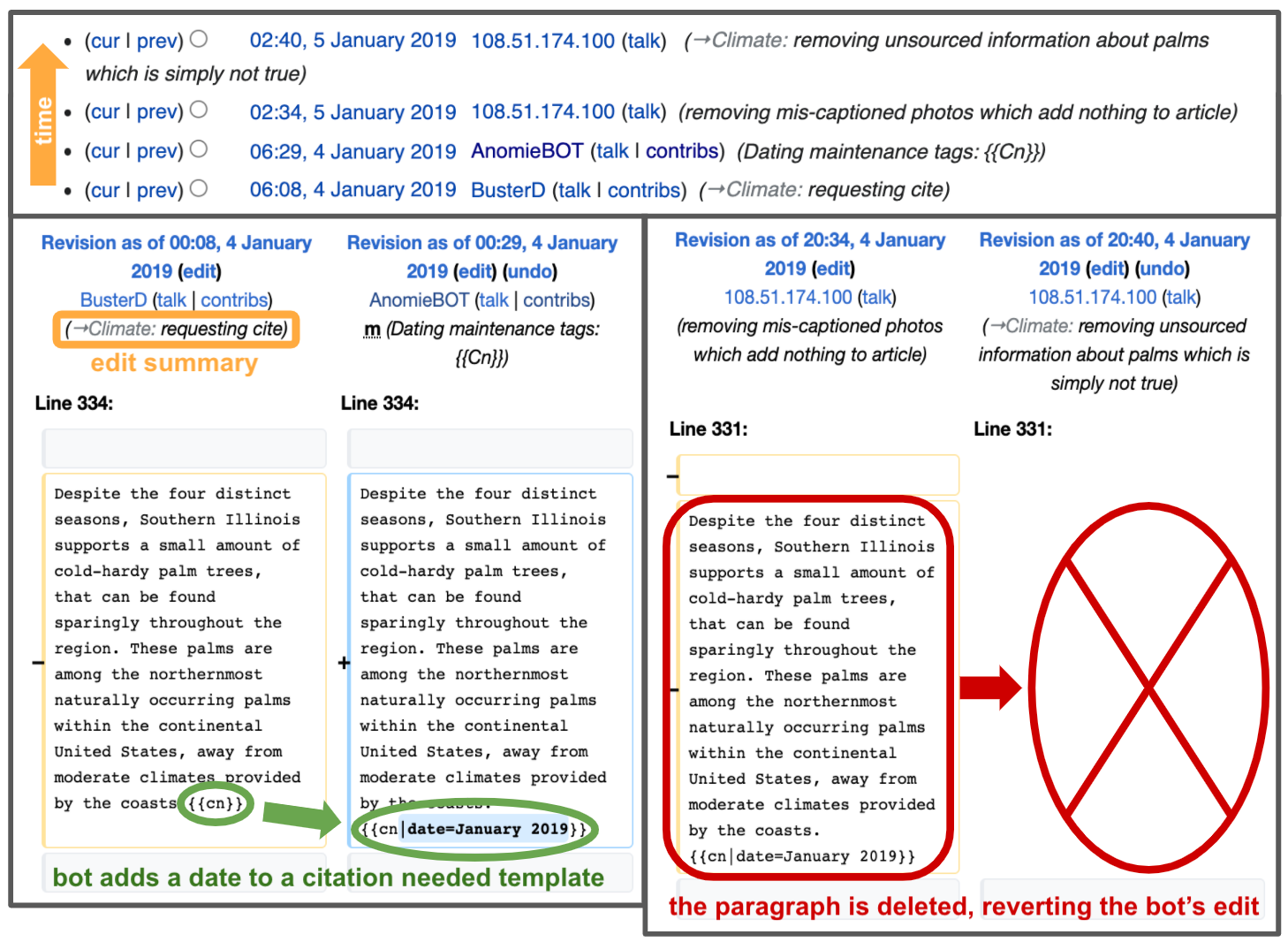
Each time a user (human or bot) makes a change to a Wikipedia page, other users have the option to undo that change. An edit undoing or reversing the edits of another user, partially or completely, is called a revert. This type of interaction between users is interesting because the revert could indicate conflict: a disagreement over what’s included on a page. However, the original edit could have been a mistake, the original edit could be a temporary one meant to be reverted later, or Wikipedia practices could have changed and rendered the original edit unnecessary. Determining if a revert actually indicates conflict can be difficult.1
Bot-bot reverts—when a bot edit is reverted by another bot—are common on Wikipedia. A number of routine processes that bots do demand that they revert each other’s edits.2 However, the research paper “Even Good Bots Fight” by Tsvetkova et al. considers reverts to be a strong indicator of conflict. Their study concluded that the many cases of bots reverting each other indicates Wikipedia’s lack of control over its bots and led to media coverage of raging bot wars. Geiger and Halfaker’s replication study critiqued the association of bot reverts as necessarily indicating bot conflict. Through a mixed-methods approach, they argue that bot-bot reverts are primarily routine work, with the vast majority of bots acting as intended and in collaboration with each other. We build on their research by inspecting how four of the most prolific bots use reverts to interact with both bot and human editors. By studying these bots and their reverted edits, we also found that reverts didn’t indicate conflict, which indicates the importance of looking at reverts in context.
To conduct our analysis, we looked at edits made to English Wikipedia in the first three weeks of January 2019. We looked at a random sample of 10 edits for each bot, using our conclusions and other summary figures to choose samples for further analysis.3 In our study, we considered a revert to be any edit that causes the page to be an exact match of a previous version of the page within 24 hours. Thus we only look at reverts that completely remove the content of the original edit. By this definition, multiple edits can be undone by a single revert; in fact, 71% of reverts undo multiple edits at once. We define a self-revert as a revert where the original edit and the reverting edit were made by the same user. In the next four sections, we’ll dive into four different bots as case studies to understand whether bots’ reverts indicate conflict.
AvicBot
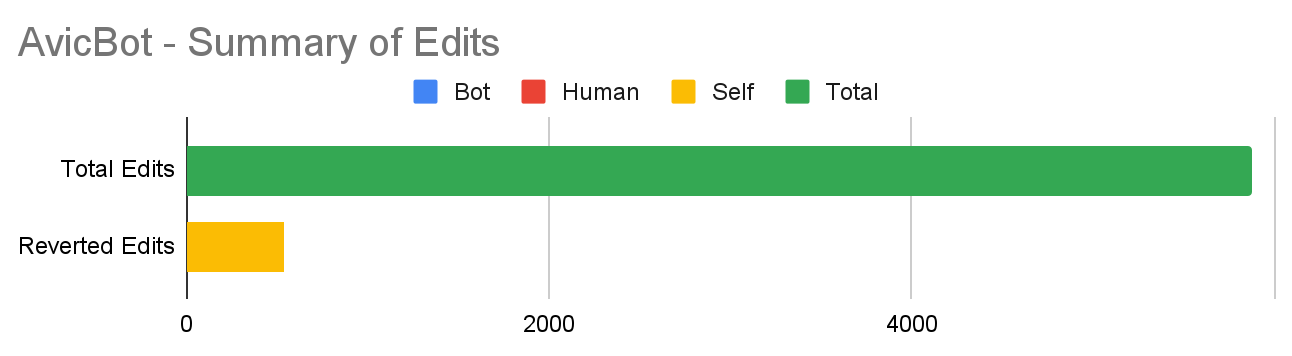
One of the bots that we looked at extensively is AvicBot, which is among the top 5 self-reverters. AvicBot is run by the user Avicennasis and has been operating since 2011.4 The bot has not made an edit since June 26, 2020 and was officially marked inactive on April 20, 2021. AvicBot performed a total of 11 tasks, including but not limited to: maintaining interwiki links, fixing redirects, tagging certain pages, maintaining a list of certain categories and more. Based on our analysis, AvicBot appears to be primarily a “listifying” bot because it maintains several tracking categories.5
AvicBot reverts itself while doing its routine listifying work. For example, when we look at this revision and its corresponding revert, the edit summary indicates that the revision is creating a list from a category of pages flagged for deletion. Another user was added to the page and 45 minutes later, after several intervening edits, the revision that reverted the original edit removed 4 entries, including the one added during the original edit. As we can see here, multiple of AvicBot’s edits were undone by a single revert. The bot is self-reverting here to periodically update the category its tracking!
As many of AvicBot’s tasks involve maintaining tracking categories, we can infer that most of AvicBot’s edits will probably look similar to the edits we looked at. All of AvicBot’s reverted edits are self-reverts, because it’s constantly updating several categories and reverting its own revisions. Thus we have concluded that the vast majority of AvicBot’s self-reverts are routine work and do not indicate conflict
Cyberbot I
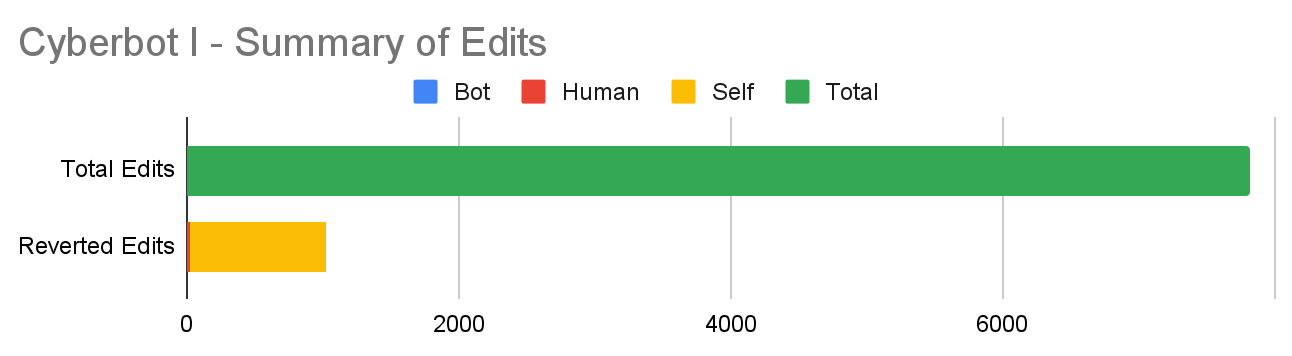
Cyberbot I has the highest percentage of reverted edits of the 4 bots, with 13% reverted edits. Cyberbot has been running since April of 20126 and remains active as of July 2021. The bot is maintained and operated by Wikipedia user Cyberpower678.7 Based on our data, Cyberbot I’s primary task appears to focus on updating various tables of statistics to keep Wikipedians updated of activity on the encyclopedia.8
97% of Cyberbot I’s edits are self-reverted: why? To find out, we selected at random 20 self-reverted edits. 18 of those edits were on the Cyberpower678/Tally page, which Cyberbot I appears to use to keep track of the current number of votes in RfA and RfB discussions, though the purpose of the page is not clearly stated. The edits present as reverts because the bot seems to repeatedly delete its own content from the page, then add the same content again. The other 2 edits in the self-reverted sample were on the RfX Report page, where Cyberbot I also deletes its own content just to add it again seconds later in order to update the page. These edits are not problematic because the bot appears to be doing its job and functioning as-intended. Not all of Cyberbot I’s reverted edits are due to self-reverts: 26 edits were reverted by humans. The vast majority of these edits did not seem problematic and were often related to Cyberbot’s Sandbox cleaning task.9
Out of all Cyberbot I’s edits, we found 7 edits that are possibly problematic, either as malfunctions of the bot or disagreements over what the bot should be doing. The first problematic edit occurred when Cyberbot I updated a user’s admin stats but the edit count went down instead of up, which is impossible. This edit appeared to go unnoticed for the 24 hours it was visible. Cyberbot I also added an Articles for Deletion template to an article whose discussion had already closed, which was reverted by a human an hour later. The bot also deleted all content on the Changing username/Simple pagetwice, which was reverted by a human in about 2 hours each time. In a problematic sequence of 6 edits on the Template:RfX tally page, human users attempt to change the page and are reverted by the bot each time, reverting Cyberbot I in turn until a human moves the page to circumvent the bot. Overall, these represent the only instances of potential conflict we identified involving Cyberbot I; the vast majority of its edits are productive contributions.
RonBot
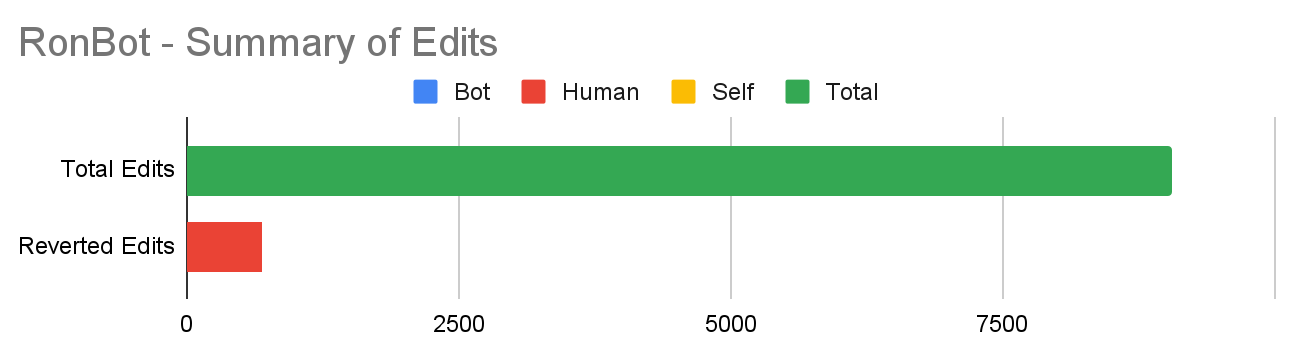
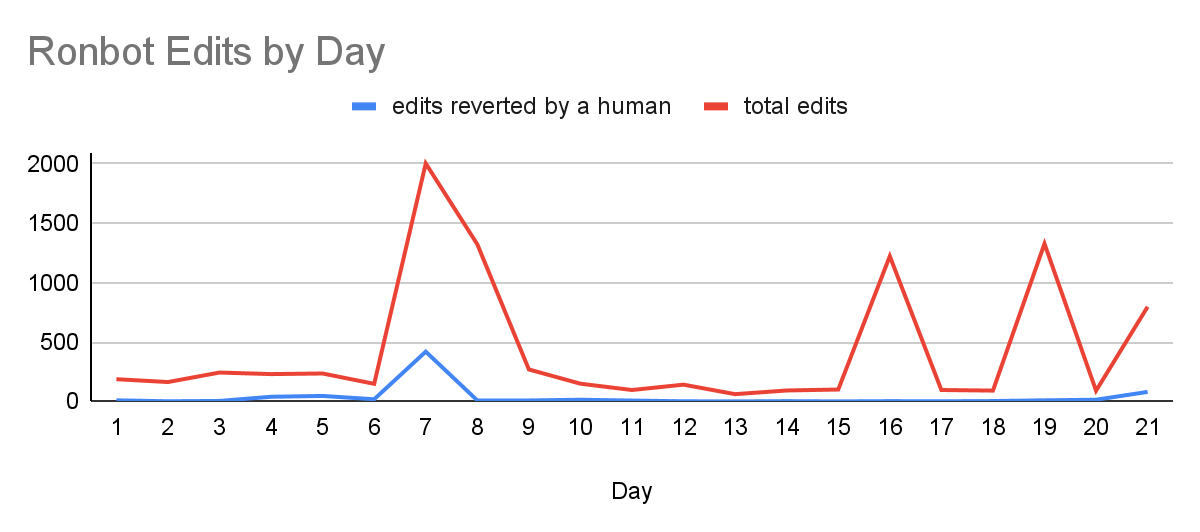
RonBot was frequently reverted by humans in our sample, coming in 3rd place in the list of bots most reverted by humans with 429 edits being reverted. It was run by Ronhjones. Due to the passing of its operator, the bot was recently deactivated and retired. We wanted to understand why RonBot was reverted by humans so often.
When we looked at 20 random edits reverted by humans, we found that 90% of these edits appeared to be caused by a malfunction of the bot. It appears that RonBot was adding articles to the “American footballers with no declared position” maintenance category10. However, users noticed that most of these footballers already had a position category listed in their articles, so these edits were reverted. We can see from the figure below that RonBot made the most edits on January 7, 87% of which were reverted. Of the 87% reverted edits, 20% of those were done by humans. Based on our qualitative analysis, it’s clear that RonBot was malfunctioning.
When a bot malfunctions, non-admin users can report them on this page. Users did report the bot’s malfunction, requesting that it be blocked or deactivated temporarily until the issue was resolved. About 2-3 days later, Ronhjones seemed to be working on repairing the bot. When we looked at another random sample of RonBot’s edits, the bot was removing this category11 from multiple pages (a number of which have been added on January 7th or months before) and fixing edits made from its malfunction, on January 8th, 16th, 19th. As we can see on the graph, after January 7th, these three dates have the highest number of total edits per day. These edits weren’t considered self-reverts, as one can see from the graph, because RonBot reverted them after 24 hours. In this special case, reverts were crucial to identifying this malfunctioning bot, and indicated malfunction rather than conflict. We suggest that a clearer reporting mechanism may be useful for improving bot governance.
AnomieBOT
AnomieBOT12 ranked 3rd on the list of bots frequently reverted by humans, so for this bot we primarily looked at article edits reverted by a human in order to understand the cause of these reverts. AnomieBOT has been editing Wikipedia since 2008 and is still active as of July 2021, operated by the user Anomie.
In a sample of 20 edits in the article namespace that were reverted by humans, we came across examples of 3 distinct tasks, as defined by the bot’s edit summary: dating maintenance tags,13 rescuing orphaned references,14 and fixing reference errors.15 None of these tasks are controversial in any way, since they are all routine maintenance. So why are these edits being reverted?
We consider at least 75% of these reverts to be caused by human conflict or human error. The sequence of events often starts with a human making an edit that others don’t like, perhaps adding incorrect or poorly formatted information. The bot then does its job and tries to help this first human by fixing some of the reference errors or adding a date to a maintenance tag. Later, a second human editor comes along and sees the mess created by the first human, and chooses to revert that human’s edit along with AnomieBOT’s edit. The fault lies with the first human: the bot’s edit is irrelevant to the human’s decision to revert. Thus, AnomieBOT is frequently reverted along with other edits made by humans because a human made a controversial edit and AnomieBOT was just caught in the crossfire of a human disagreement.
In the article namespace, 93% of AnomieBOT’s edits reverted by humans were reverted at the same time as a human edit. Because of this statistic and our qualitative observations, we believe that AnomieBOT is frequently reverted not because of conflict between the bot and humans, but because of conflict between humans and other humans. AnomieBOT is not in conflict with any other users.
Conclusion
In this blog post, we showed that reverts generally don’t indicate bot conflict. AvicBot and Cyberbot I both reveal that routine operation can involve self-reverting. RonBot was malfunctioning, which most people wouldn’t consider to be conflict. AnomieBOT reveals that just because a bot is being reverted doesn’t mean it’s involved in conflict; it may just be getting in the way of two human editors’ conflicts! Our research suggests that people attempting to quantify bot conflict need to develop more sophisticated methods than just counting reverts.
This research would not have been possible without the help of our mentors: Professor Loren Terveen and soon-to-be-PhD Zachary Levonian in the GroupLens Lab at the University of Minnesota. This work was also presented at the UMN Virtual Poster Symposium. Code for this work is available on GitHub.
Footnotes
When reverting another user, most human editors will leave an edit summary to indicate why they made the change. An edit summary is a short explanation of an edit that is visible in the article’s edit history, shown in the top panel of the image below. Bots are also required by the bot policy to leave descriptive edit summaries, but their edit summaries are pre-programmed in their code. Thus if the bot is malfunctioning, the edit summary may not match what they’re actually doing.
For example, DatBot reports users who break community guidelines. Meanwhile, HBC AIV helperbot 5 checks if reported users have been blocked, and if they are, the bot removes the entry. Hence, reverting DatBot’s edits is a part of HBC AIV helperbot5’s job.
For more information on our sample, we have provided summary information here.
Cyberpower678 also operates a second bot, Cyberbot II. It appears that all of the code and tasks of Cyberbot I belonged to other bots previously, based on the bot’s approvals and user page, though the operator has rewritten and maintained the code.
For example, Cyberbot I updates a separate Adminstats page for any user who requests these statistics. Other examples of tables maintained by the bot are the RfX Report page, which tracks any current discussions about requests for adminship or bureaucrat status, and the Requests for Unblock table, which keeps track of Wikipedians who would like to be unblocked from editing. In addition to maintaining these statistics pages, Cyberbot I clears various sandbox pages, which provide a space for users to experiment with editing tools without damaging Wikipedia articles; maintains several discussion pages, including Articles for Deletion and Changing username/Simple; and creates the current events page featured on the Wikipedia Main Page every day. Many more tasks are listed on Cyberbot I’s user page.
The Sandbox functions as a sort of whiteboard, where Wikipedians can test out their editing skills as they wish. Later, a bot will come wipe the whiteboard clean so that the next person arrives to a clear editing space. Some Wikipedians like to keep their content in the Sandbox for a while though, so will revert Cyberbot to restore their content to the Sandbox.
A maintenance category is specifically used so that Wikipedia contributors know that a given article needs some kind of maintenance. These categories are not visible in the article page, but must be included on the source code of each article. The “American footballers with no declared position” category is presumably used so that contributors will come to the article and add it to a position category, such as “Association football forwards.”
The “American footballers with no declared position” category
This bot operates out of 5 different accounts, each with various privileges and edit spaces, but our analysis was focused on the main AnomieBOT account.
Also called maintenance templates, these tags allow editors to leave messages for others about problems with a given article. The tags can be dated so that editors know how long they have been on the page. An old tag may be deleted if it becomes out of date or no longer relevant to the article. AnomieBOT adds dates to these maintenance tags so that humans know when they were added to the article.
The Wikitext language used to write Wikipedia articles requires the use of a reference template in order to cite information. References can be named so that they can be used multiple times in a document without having to copy the source information multiple times. An orphaned reference is a reference which has a name, but no accompanying reference information in the article. AnomieBOT attempts to recover information about the reference from the page history and add it to the article.
Similar to rescuing orphaned references, reference errors are often caused by issues with the reference template required by Wikitext, the language used to write Wikipedia articles. When a human makes a reference error, AnomieBOT recognizes these errors and attempts to fix them so that the article has fewer problems.
We all have dark thoughts sometimes. And if you’ve ever been a graduate student, perhaps thoughts like the following feel familiar:
The thoughts in this image are real data points collected during deployment of a prototype called Flip*Doubt, an app in which negative thoughts are entered and then sent to three random crowd workers to be “positively reframed” and sent back to the user. (The full paper title is “Effective Strategies for Crowd-Powered Cognitive Reappraisal Systems: A Field Deployment of the Flip*Doubt Web Application for Mental Health” and you can read it here.)
Rates of mental illness continue to rise every year. Yet there are nowhere near enough trained mental health professionals available to meet the need–and Covid-19 has only worsened the state of affairs. In short–we urgently need to rethink how we design mental health interventions so that they are more scalable, accessible, affordable, effective, and safe.
So, how can technology create new ways to expand models of delivery for clinically validated therapeutic techniques? In Flip*Doubt, we focus on “cognitive reappraisal”–a well-researched technique for changing one’s thoughts about a situation in order to improve emotional wellbeing. This skill is often taught by trained therapists (e.g., in Cognitive and Dialectical Behavioral Therapy), and it has been shown to be highly effective at reducing symptoms of anxiety and depression. The problem is, it’s really hard to learn, and even harder to apply in one’s own mind on an ongoing basis.
We envision that people could learn the skill through practice by reframing thoughts for each other–since research shows that it’s easier to learn by objectively sizing up others’ thoughts, rather than immediately trying to challenge your own entrenched ways of thinking. Thus, Flip*Doubt relies on crowd workersto create reframes, and the major driving questions of our study were: What makes reframes good or bad? And how can we design systems that effectively help people to nail the skill?
Our deployment yielded some fascinating results about how people use cognitive reappraisal systems in the wild, the types of negative thought patterns that weigh grad students down, and what types of strategies are most effective at flipping dark thoughts. For instance, the example below shows how a participant rated three reframes from Flip*Doubt:
Represented here are three different reappraisal tactics for transforming the original thought that we identified through our data analysis. “Direct negation” isn’t effective at all–it’s just invalidating and frustrating for someone to suggest the opposite of what you’re struggling with. “Agency” rings more true–yet can feel a bit simplistic. “Silver Lining” wins the gold for this thought–it provides fresh perspective by emphasizing an important positive that wouldn’t be possible without all the struggle. Our paper provides additional analyses, culminating in six hypotheses for what makes an effective reframe.
Our work suggests several important design implications. First, systems should consider prompting for structured reflection rather than prompting for negative thoughts. People aren’t always thinking negatively, and only allowing negative thoughts for input can reinforce those thoughts, or drive people away. Second, systems should consider tailoring user experiences to focus on a few core issues, since the best gains may come if meaningful progress can be made to address vicious and repetitive thoughts, rather than any old negative thought. Finally, crowd-powered systems can be safer and more effective if we design AI/ML-based mechanisms to help peers shape their responses through effective reappraisal strategies and behaviors–there’s a lot more on this in the paper, so we hope you’ll read about it there.
Everything changes in a heartbeatwhen you or someone you love receives a life-threatening health diagnosis.
Research from the medical and nursing fields repeatedly shows that people turn toward religion or spirituality to cope, even if they didn’t necessarily see themselves as “spiritual” during their lives. Many people wish they could go back and apply lessons learned earlier in their lives, so that they could live more fully and be better people. What if technology could help with that? To embrace the aspects of our experiences that most provide us with a sense of meaning, hope, and fulfillment–however we each individually define that?
CaringBridge.org is a nonprofit health journaling platform that offers a free service similar to a blog, but with specialized tools and privacy controls to facilitate social support during serious or life-threatening illness. Our prior research showed that prayer support is more important to CaringBridge users than any other form of support [1]. Although HCI research has largely ignored religion and spirituality for decades [2-5], our #CSCW2021 paper follows up on this finding to ask, beyond prayer, “What is Spiritual Support and How Might It Impact the Design of Online Communities?” (Full paper here.)
Through participatory design focus groups with CaringBridge stakeholders, we derived the following definition:
Spiritual support is an integral dimension that underlies and can be expressed through every category of social support, including informational, emotional, instrumental, network, esteem, and prayer support. This dimension creates a triadic relationship between a recipient, a provider, and the sacred or significant, with the purpose of helping recipients and providers experience a mutually positive presence with each other, and with the sacred or significant.
The point is, when our aim is truly to support someone who is struggling, a fundamental underlying element of love and connection needs to transcend specific beliefs. Take prayer, for example. If you’re Christian, prayer might just be the most meaningful way someone can help you. If you’re an atheist, though, prayer could be quite an offensive way of expressing support. One implication is that in sensitive health contexts, designers might consider ways to help people represent their beliefs, so that supporters can craft expressions of care and support that respect them.
Building on this concept of expression, our results also highlight that even when spiritually supportive intentions are there, it’s difficult to respond to devastating news—so, participants wanted technological assistance with writing helpful comments. A second implication–which could span many types of online communities–is that commenting interfaces could embed mechanisms such as training resources, tips, or possibly automatic text recommendations. Future research will need to investigate how to design such features without damaging the meaningfulness and authenticity of comments.
Stakeholders also envisioned future systems that could create more immersive sensory experiences–e.g., by visualizing spiritual support networks and all the specific types of support they can provide (ps. check out this awesome viz project by Avleen Kaur on the topic!)–or that could even help people come to terms with their mortality and plan for a time beyond their final days–e.g., by designing mechanisms that aid users to configure advance planning directives and to mindfully sculpt the digital legacies they will leave behind. Read the full paper or watch our video presentation to learn more about these fascinating implications.
I’ll close on the note that, for a topic like this, a scientific paper truly cannot convey the depth and richness of participants’ experiences. So, I worked with artist Laura Clapper (lae@puddleglum.net) to illustrate a few special quotes from our data that highlight what spiritual support means to people–both online and offline. I’ll let these stories speak for themselves, and I hope to see you at our session at #CSCW2021.
“An older woman had just been admitted, and she had a kind of a rough night and didn’t feel great. She was just near tears. An aid was in the room, and they were talking about religion. They were the same religion. And the aid got down on her knees and held the woman’s hand and she said, “Can I pray for you when I go home?” It was towards the end of the shift, and the woman, I thought she was going to cry. She just changed her whole tone. It just gave her an extra bit of hope, and I think it was a kind thing to do.”“My husband was in the hospital, having had a massive motorcycle accident. He was one of those, “Will he make it for the first 24 hours? We’ll see…” And I had a friend start a CaringBridge site. He was in the ICU for almost two weeks. This is the description I came away with–it’s like riding the wave of love. That’s what it felt like. Both of us could feel this support, that was in the writing. Later, when people stop writing because you’ve gotten better, you can feel that diminishing. That was very, very tangible.”“For us, receiving meals was spiritual support because the people who would come to deliver food, it wouldn’t be an expectation of sitting in our house and us entertaining them. But they would just kind of give her a hug or something. And it was quick. And it was loving. And to us, it wasn’t even about the food. It was just kind of, them doing something out of love, taking time out of their day, showing that they care.”“When I was an oncology nurse, I had different experiences with patients, right before they’re dying. I had one moment when somebody had cancer, and she had been lying there, kind of unresponsive. But then this morning, she woke up, and I was like, “Hey, do you want to stand up? Let’s brush your teeth. Let’s get you cleaned up.” I got her back in bed, then her husband came, and I was like, awesome, he’s gonna see her awake, and she just kept smiling. And I was like, “What are you looking at? Do you see something?” And she’s like, “I see three beautiful beings.” And I said, “You look so peaceful,” and she goes, “I’m so peaceful.” I said, “You look happy, are you happy?” And she said, “I’m so happy.” And she ended up dying later that day, and I was like, the husband got to hear her say, “I’m happy, I’m at peace.”“Even though I have a lot of experience providing spiritual support, one of the experiences that most sticks out to me was that my father had ALS and he was 84. The doctors said it will be relatively quick. I had been out about six weeks before he passed away, and had just started my chaplain internship. Somebody came and found me on oncology and pulled me out from a patient and said, I’m saddened to tell you this, but your dad died. And it was a… I just broke down and I said, “I thought I was ready.” This oncologist, who I didn’t think really knew who I was, or you know, was all business, stopped in her tracks and just put her arms around me and said, “Don’t worry about anything. Just go take care of yourself and your family, we’ll take care of everything else.” The night I got back from my dad’s funeral, I was on call, and I got a call at midnight, 96 year old woman, she had keeled over the family dinner. After a couple hours in the ER, doctor said, “We gotta call it, there’s not much we can do.” So we gathered the family together. So I went from caring for, to being cared for, to caring for–so, giving and receiving, all in a 72-hour period.”
Citation: Smith, C. Estelle, Avleen Kaur, Katie Z. Gach, Loren Terveen, Mary Jo Kreitzer, and Susan O’Conner-Von. “What is Spiritual Support and How Might It Impact the Design of Online Communities?” Proceedings of the ACM on Human-Computer Interaction 5, no. CSCW1 (2021): 1-42.
References:
[1] Smith, C. Estelle, Zachary Levonian, Haiwei Ma, Robert Giaquinto, Gemma Lein-Mcdonough, Zixuan Li, Susan O’Conner-Von, and Svetlana Yarosh. “” I Cannot Do All of This Alone” Exploring Instrumental and Prayer Support in Online Health Communities.” ACM Transactions on Computer-Human Interaction (TOCHI) 27, no. 5 (2020): 1-41.
[2] Wyche, Susan P., Gillian R. Hayes, Lonnie D. Harvel, and Rebecca E. Grinter. “Technology in spiritual formation: an exploratory study of computer mediated religious communications.” In Proceedings of the 2006 20th anniversary conference on Computer supported cooperative work, pp. 199-208. 2006.
[3] Bell, Genevieve. “No more SMS from Jesus: Ubicomp, religion and techno-spiritual practices.” In International Conference on Ubiquitous Computing, pp. 141-158. Springer, Berlin, Heidelberg, 2006.
[4] Bell, Genevieve. “Messy Futures: culture, technology and research.” In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems. 2012.
[5] Buie, Elizabeth, and Mark Blythe. “Spirituality: there’s an app for that! (but not a lot of research).” In CHI’13 Extended Abstracts on Human Factors in Computing Systems, pp. 2315-2324. 2013.