Can recommendation systems help people find support online?
Back in 2021, a team of GroupLens researchers did a study looking at the feasibility of peer recommendation interventions for health-related social support. The published paper just won a Best Paper award at CSCW 2025, so I want to tell you about the system we built and why we think researchers should build recommendation systems to help people find online support.
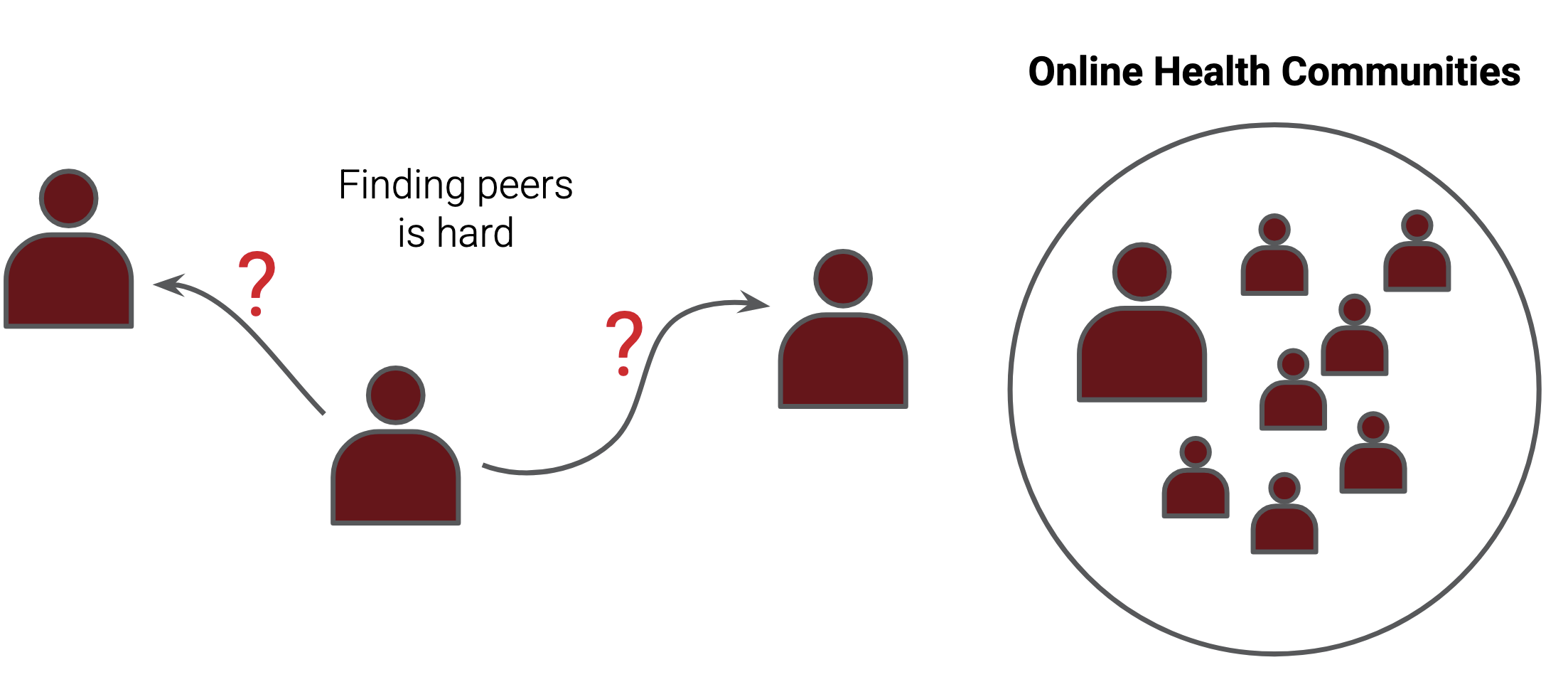
Social support is a key determinant of mental and physical health. We also know that support is particularly important during health journeys. But, a lot of the social support that people undergoing a health journey might benefit from is unavailable in their existing support networks. In particular, people benefit from support specifically from others with similar but potentially uncommon experiences.
Unfortunately, actually finding and connecting with these people – with peers – is logistically hard. For example, it’s one of the reasons hospitals organize condition-specific support groups. Fortunately, the internet exists!
Online communities organized around health (creatively called online health communities) offer the promise of a space where people can seek and receive support. But even in online health communities we have a discovery problem.
Imagine a highly-motivated support seeker:
I have some kind of support need in mind.
I’m interested in connecting with peers.
…now I need to wade through thousands of forum threads.
Not great.
There are a lot of design opportunities here, but a suggestion that comes up again and again is recommendation.
Read a Computer-Supported Cooperative Work paper looking at an online health community, one of the design implications will probably involve improving peer recommendation systems. (I wrote a paper like that too.) But empirical research on systems designed for connecting peers in online health communities is remarkably rare.
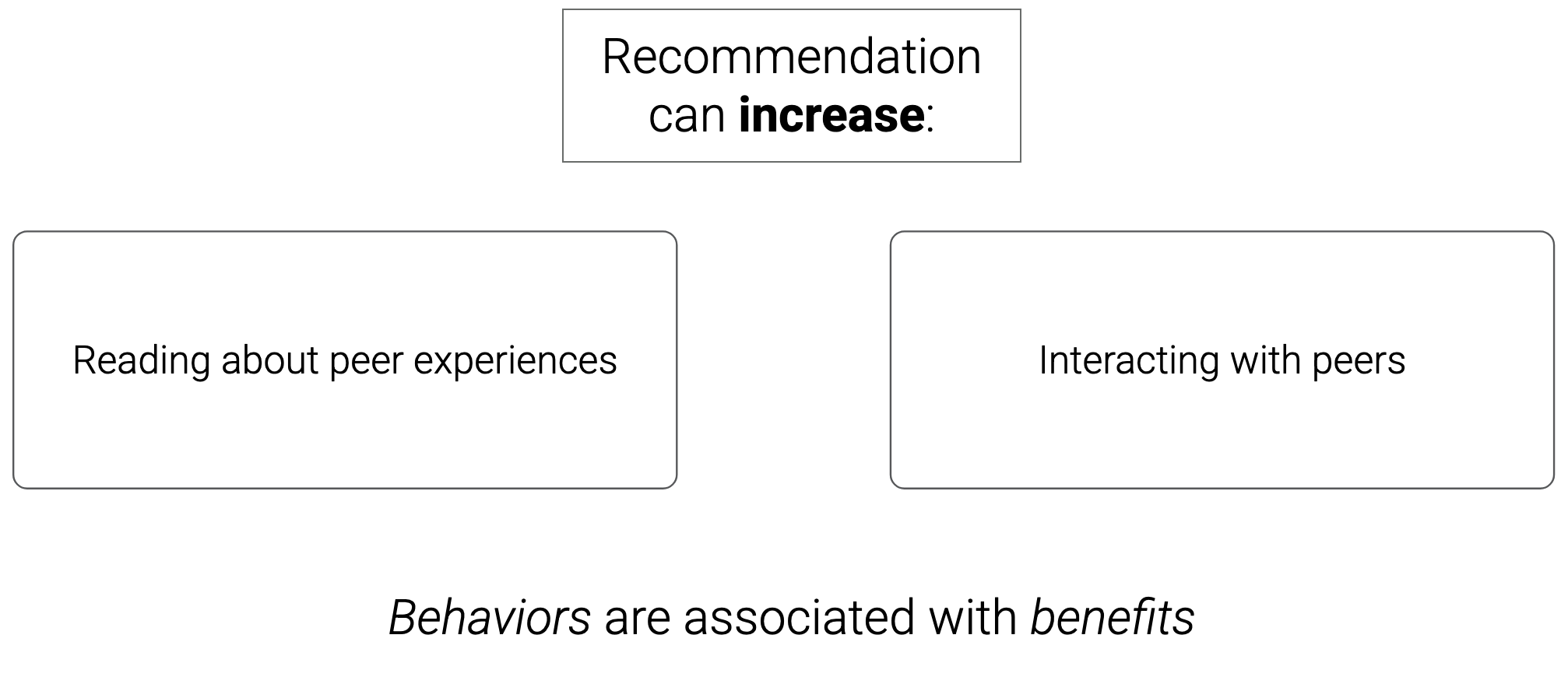
My challenge to the community is to treat recommendation as a serious intervention into people’s social networks. That means we need to design the intervention with particular health benefits in mind.
In this case, we’re designing our intervention to increase two behaviors that are plausibly associated with health benefits:
Reading about the experiences of peers
Interacting with peers
In general, we don’t know that recommendation will actually increase these behaviors, nor do we know that increasing these behaviors is actually linked with health benefits. This is a classic “causal gap”: we have some associational evidence that manipulation could help, but no strong causal evidence.
The associational evidence is quite good. For example, we ran our study on CaringBridge.org, a health blogging platform. On CaringBridge, receiving interactions from peer blog authors was associated with an additional 6 blog posts and an additional 3 months of activity on the site.
That’s a huge effect size… if there’s a strong causal relationship between peer interaction and engagement.
What we want is to evaluate efficacy. Will the recommendation intervention actually increase desired behaviors? The conventional next step is to run a randomized controlled trial (RCT). But running an RCT is hard and expensive! There are too many open questions about the intervention, and too many degrees of researcher freedom to collect high-quality evidence. Instead, let’s run a feasibility study first.
This concept comes mostly from the health sciences (see Bowen et al. 2009) and is greatly underused in human–computer interaction research. We will try to collect some data about efficacy, but our focus is on all the preliminaries:
The demand for the intervention
The acceptability of the intervention to participants
How practical and adaptable the intervention is
Specific challenges in implementation
Our goal is to triangulate overall feasibility by collecting evidence in each of these areas.
System design
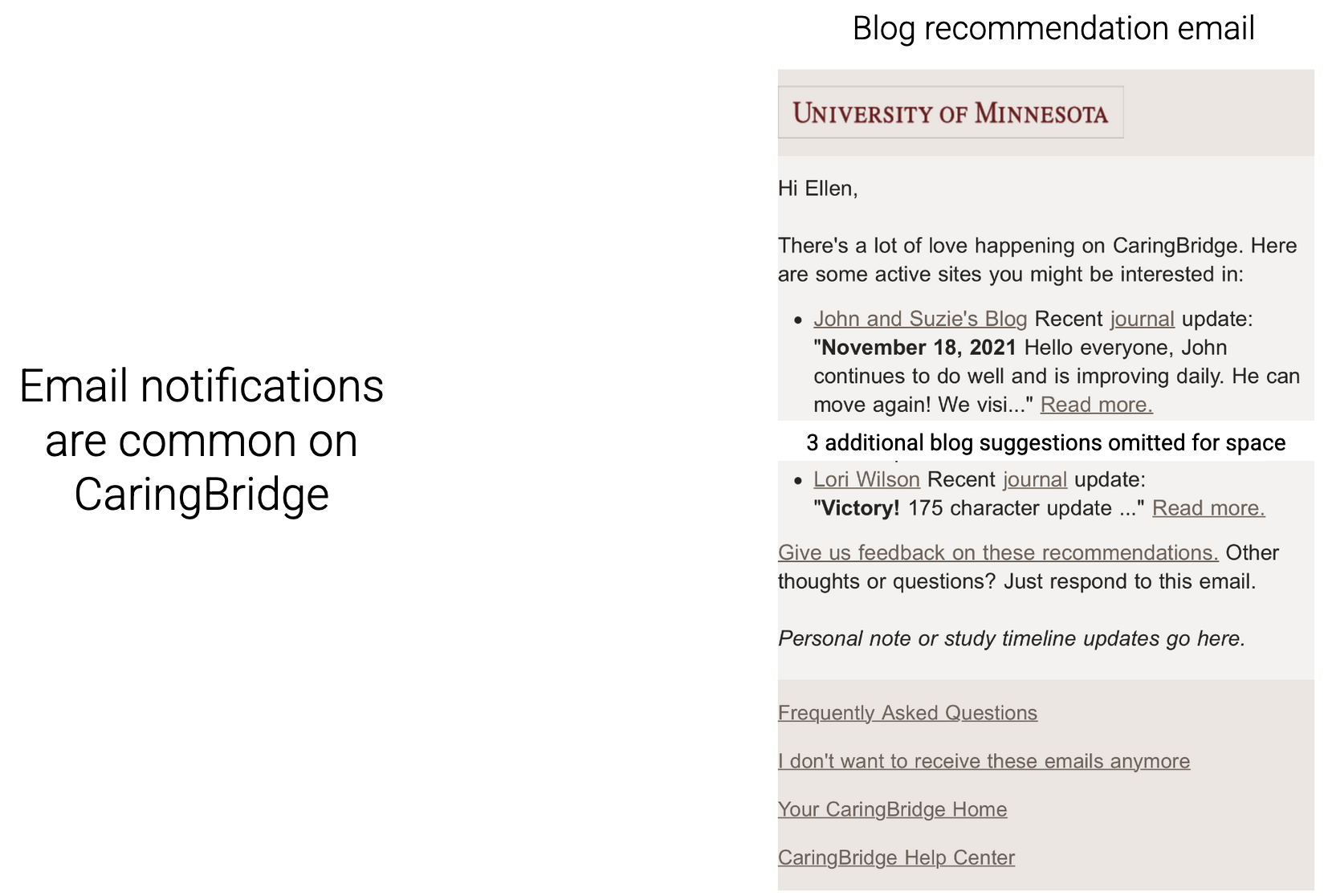
By embracing the feasibility study mindset, we want to be practical. Email notifications are common on CaringBridge. So, we copied the design of existing author notifications into a new “blog recommendation email” with five links.
To generate recommendations, we trained a deep learning recommendation model from historical interaction data we already had. The goal of a feasibility study is to surface useful insights, so we also did a bunch of experiments about what data it’s useful to have if you’re trying to do this… see the paper appendices for details.
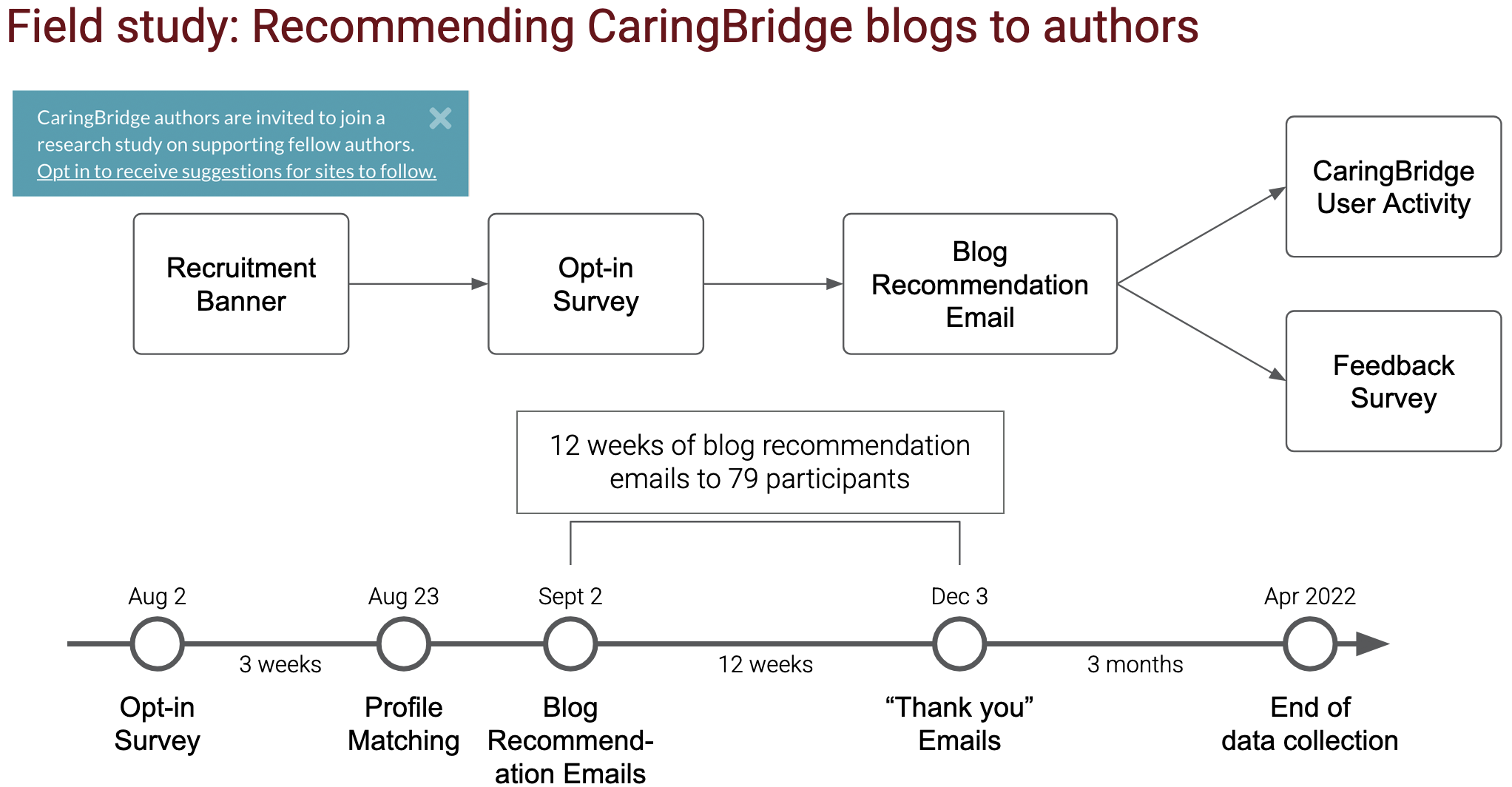
Field study
We threw up a recruitment banner and got CaringBridge authors to take a survey. We got 79 people to sign up for 12 weeks of emails. Then we collected data for 3 months after the study so we could estimate efficacy over a slightly longer term.
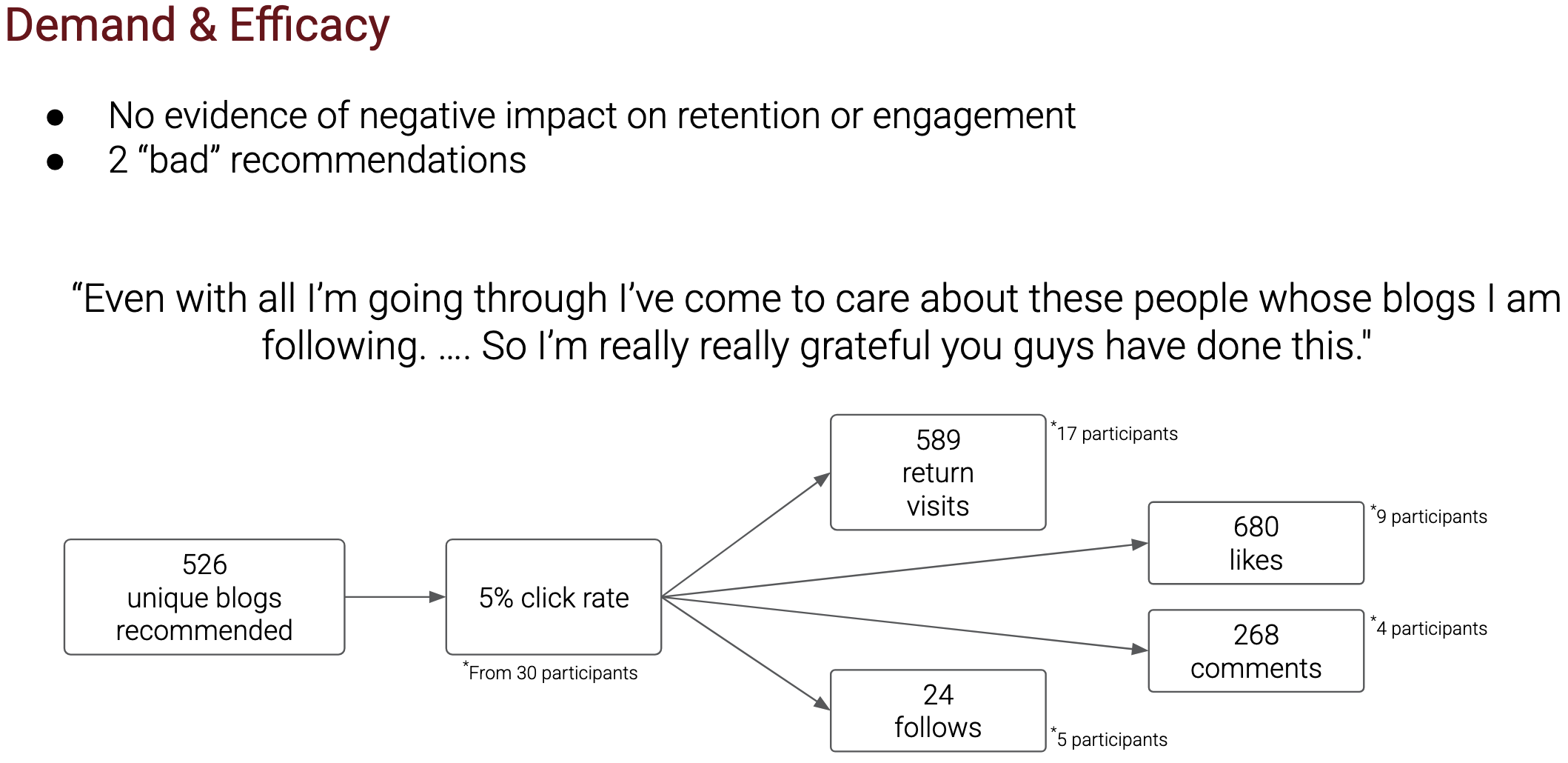
Here are our results, condensed into one image:
No apparent harms, either qualitatively or in terms of retention and engagement. One participant objected to 2 recommendations, otherwise people mostly didn’t give us feedback on the recommendations. We also heard some really nice feedback from participants.
Recommendations didn’t seem to hurt, and they caused hundreds of new likes and comments. Now, we have the confidence to do a full-blown RCT.
During this study, we learned a bunch of fiddly, practical things that I hope will be really helpful for other people designing peer recommendation systems. If you’re interested in peer recommendation or peer matching at all, check out the paper for more details.
Zachary Levonian, Matthew Zent, Ngan Nguyen, Matthew McNamara, Loren Terveen, and Svetlana Yarosh. 2025. Peer Recommendation Interventions for Health-related Social Support: a Feasibility Assessment. Proc. ACM Hum.-Comput. Interact. 9, 2, Article CSCW146 (April 2025), 59 pages. https://doi.org/10.1145/3711044
This post was originally published on Zach Levonian’s blog and is an adaptation of Zach’s CSCW 2025 presentation, which is available on YouTube. A shorter summary was previously published here.
Creating a PhD website lets others see your publications, research area, and personality! However, it is a daunting task. I was prepared for a big hassle when my advisor tasked me with setting up a personal website, but I ended up publishing my site within minutes using the following method.
Base Tutorial
A few months ago, Notion began letting users publish their Notion pages on the web for free. Notion has a tutorial on how to do this, but it’s bloated with instructions about paid features. The process only requires a dozen clicks:
Step 1: go to “Settings & members” > Sites > “New domain” and set up a Notion domain
Step 2: go to whatever page you want to publish, click “Share” in the top right, then publish and choose the new domain you made
Step 3: set up the search engine indexing. This makes it so the site will pop up if someone Googles you.
Making Your Site Pop!
When it comes to the page itself, you’ll want to start with a template. I couldn’t find any templates for academic personal sites (probably due to the hosting feature being so new) so I started with Notion’s official personal website template:
Notion’s Personal Website template
I noticed that a lot of Notion templates look similar, but one thing that distinguishes them is the “cover” at the top of the site. Covers with interesting shapes really caught my eye, like this one in the bottom middle:
Results when you look up “Personal Site” in Notion’s template gallery
I think that as HCI researchers, we’re held to a higher standard when it comes to UI. I knew I’d need something to distinguish my Notion site from the rest, so I decided to make my own cover.
Most of it was trial and error as I used ChatGPT to write Python scripts to algorithmically create the covers. It was kind of like using turtle with natural language.
Lots of ideas sounded good in my head but didn’t look great on the site, like this orange-to-white gradient
For some reason, I thought it would be fun to try a random “ball pit” effect. I don’t know what I was thinking
Eventually, I got an effect that I liked, mostly because it justified the amount of time I spent making covers. Setting the site to “Full width” also helped a lot. After that, I put in some placeholder text and a few sections.
In 2022, Politico reported that Crisis Text Line (CTL)–a non-profit SMS suicide hotline–-used one-on-one crisis conversations to train a for-profit customer service chatbot. In response, CTL maintained that they did not violate reasonable expectations—hotline users “consented” to a lengthy Terms of Service (TOS), which specified that CTL could use data for business purposes.
This uninformed consent procedure and irresponsible use of data is an obviously egregious move in many research circles, such as my own. However, in the eyes of the law, CTL, and many others, CTL didn’t violate any reasonable user expectations. The consensus was that, while TOS consent procedures are imperfect, it’s the cost of having free technology services. In my paper, I ask: are we still okay with paying this price?
The price here is justice—our ability to give everyone their due right. In offline settings, injustice evokes the image of human rights violations and massive inequities. However, the picture is less clear in AI settings. As we all contribute our data, knowledge, and time to AI systems, what do we deserve as a matter of justice? To answer this question, we formulated a precise theory of justice that captures current tensions between users and tech companies in AI/ML settings.
To quote John Rawls,
“A theory however elegant and economical must be rejected or revised if it is untrue; likewise laws and institutions no matter how efficient and well-arranged must be reformed or abolished if they are unjust.”
In other words, a theory of justice is an attempt to appropriately represent the state of the world, articulate societal values, and inform future change. When we have a true theory of justice, we do not need to rely on subjective moral intuitions. Rather, we can agree upon an ethical compass for building our laws and institutions.
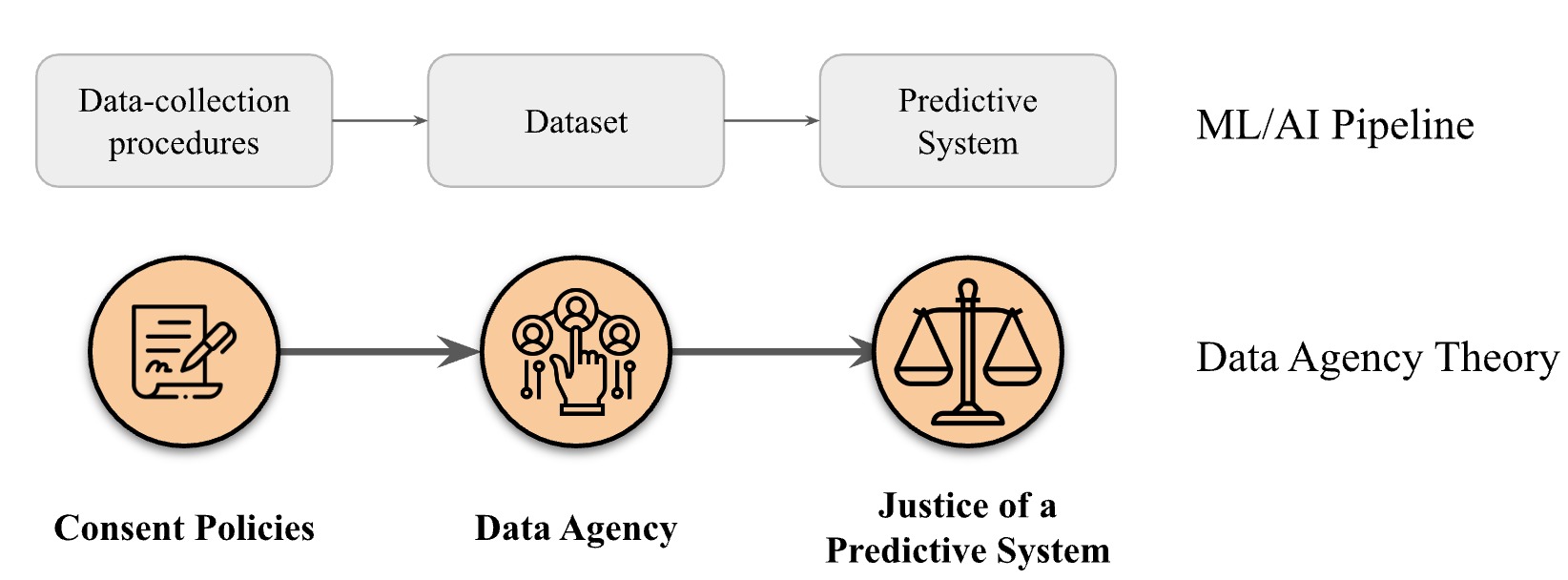
Our paper proposes data agency theory (DAT). Data agency is one’s capacity to shape action around the data they create. For example, individual privacy settings on Google increase one’s data agency by allowing users to opt into (i.e., consent to) data sharing with third-party advertisers. Data agency theory argues two premises. First, consent procedures outline data agency systematically and, therefore, are institutional. Second, inspired by justice scholars such as Rawls and Young, this institutional way of outlining data agency is a matter of justice. In sum, justice in a predictive system demands considering how institutional routines (i.e., consent procedures and terms of services) transform agency at a group level. Concisely, data agency is a contributor to justice and a product of consent policies in a predictive system.
DAT is a data-centric theory of justice that directly translates to next steps for achieving ML & AI ethics goals. As ML/AI systems need larger datasets, ethicists in the field have made numerous calls for better data management throughout the pipeline—involving questions of consent, data storage, and responsible use of predictive outcomes. However, these calls have been mostly unanswered; many social media sites still use dense Terms of Service agreements that have been criticized for over a decade. Here, we argue that this lack of action to increase a user’s data agency is not just a moral imperfection, it is injustice.
By raising the stakes of problematic consent procedures, we hope to catalyze action. In the paper, we reimagine consent procedures in two salient ML/AI data contexts: (1) social media sites and (2) human subjects research projects. For example, we imagine affirmative consent on social media sites, sustained efforts by researchers to reaffirm consent, and the ability to withdraw one’s data from benchmark datasets. AI justice demands consent procedures that proactively solve systemic information and power gaps around one’s data. This paradigm shift is crucial to evaluating current consent procedures and generating better ones.
The PhD students at GroupLens have a variety of hobbies! From knitting to playing video games, we all have non-research activities that contribute to our lives. In this article, we asked two PhD students, Leah Ajmani and Alexis Tarter, how their hobbies have helped them become more successful researchers. What does distance running and working an escape room have to do with research? Read below to find out
Leah and her dog, Yogi, finishing their first half-marathon
Lessons from Running
As a very unathletic kid, I didn’t pick up running until I was a PhD student. I’ve run numerous community races in the past two years, including a half marathon! Here’s what I’ve learned:
There’s no such thing as “junk miles”
Sometimes our runs suck. Similarly, sometimes our writing sucks, our research is going slow, or we have to miss a deadline. However, there is no such thing as junk mileage in research. All research, even the research that doesn’t end up in papers, builds our capacity to do research. In that sense, it is useful!
You have lots of different paces; the key is to switch between them
You may have heard “it’s a marathon, not a sprint” about your PhD. The advice here is to go slow and not burn out. Running has taught me to extend the metaphor one step further. I have a marathon pace, but I also have a sprinting pace. I even have a 5k and 10k pace for things in the middle! The key to not burning out is to use the right pace at the right moment.
Think about how you would run a marathon. You may have a “marathon pace,” a goal for each mile to run a certain marathon finish time. For example, my goal is to run a half-marathon in under 2 hrs and 15 min. In theory, I would need to run a 10-min mile 13.1 times. In practice, though, my first few miles would be >10 minutes so I can get into a rhythm. Then, each mile gets progressively faster so I can “ramp up.” The idea is not to just run slow. It’s to run slow at the beginning so that you can go ham and truly race in those last few miles. In a PhD, paper deadlines require you to have enough energy left in your tank to race those last few miles, so be judicious with your pacing.
Your mind will want to quit early and often
In running, we say, “Your mind will want to quit before your body does.” Obviously, if you’re injured or battling physical limitations, you should STOP RUNNING. But if the reason you want to stop running is because your mind is telling you to quit, it’s probably best to keep going.
In research, I use the “quit-three rule.” If I’m reading a paper, writing, or even running, I tell myself that I have to think, “I should quit doing this,” three distinct times before I’m allowed to give up on the task at hand. This rule gives me the ability to pivot off of things that simply will not happen at the moment while still building the resilience to do the things I want to. It’s not perfect! Sometimes, I’m phoning in the task, but it’s a good way to practice focus.
Alexis and friends finishing an escape room!
Lessons from Escape Rooms
I once worked at an escape room, and it turns out it was helpful for my PhD (and it was more entertaining than watching TV).
Ask for help earlier than you think you need to.
Often, groups would come to complete an escape room and be overconfident about their abilities. Maybe they had completed plenty of rooms in the past. Maybe they really enjoyed solving puzzles. Maybe they just thought they were particularly smart. But more often than not, those groups would perform worse than others. Why? Because they didn’t ask for help early and burned precious time on simple problems.
The same flawed thinking can occur in a PhD program. Rather than admitting to your advisor or peers that you are stuck, you may be tempted to battle against a problem all by yourself. Don’t be like those overconfident escape room groups! Asking for help and being vulnerable with others can help you tackle a problem and connect with those around you.
Answers can come from unlikely places.
“Wait…I think I’m Janet!” said my colleague. Turns out a fantastic group had been calling the escape room employee “Janet”, an all-knowing being from the show The Good Place. While, unfortunately, none of us can ask a not-a-girl, not-a-robot character the answer to any question in the universe, we can find answers in places we least expect them.
The same is true during a PhD program. While courses and your advisors are key sources for support, engaging with experiences that bring you joy is also vital. Maybe the family member you are trying to describe your project to can help you find a way to frame your research question. Maybe the crafting event on campus introduces you to another student with whom you can collaborate. Maybe an intramural pickleball game clears your mind, and you discover the next direction for your dissertation topic. A PhD program is a time to explore not only intellectually but also personally.
Communication is key.
Escape rooms are all about effective communication, whether it is joining hands to close a circuit, yelling out numbers from around a corner, or describing what’s inside a hidden room. It is astounding how many times I’ve seen a teammate find the key to solving a puzzle and put it silently in their pocket. As one of my favorite characters states, you have to “talk it through, as a crew.” – Stede Bonnet, Our Flag Means Death.
And, as I am sure you’ve noticed the trend by now, the same applies to a PhD program! Unfortunately, some lab and campus cultures discourage meaningful connections and collaborations. It is crucial in those situations to find people you can communicate with such as a support office or friends and loved ones. However, in all situations, it is how we talk to ourselves and with others that often determines how successful we can be.
Whether it’s running, escaping, or even knitting, inspiration is everywhere for being a successful researcher! Which hobbies have helped you as a PhD?
Reddit is no stranger to conflict between its users, but in its most recent controversy, the company found itself playing the antagonist. In June 2023, Reddit made headlines for being the subject of one of the largest scale protests by users of a site — the Reddit blackout. However, not much is known about the effects of the event on Reddit’s communities. This semester, I began exploring how the culture of support-seeking subreddits was impacted by the blackout.
Image from the Wikimedia Commons
The Reddit Blackout
On June 12, 2023, more than 7,000 communities on Reddit went private — making them inaccessible to non-subscribers. The collective disabling and restricting of subreddits is known as a Reddit “blackout.” The decision to organize this blackout was largely made in protest of the company’s decision to charge for API access. Moderators fulfill their duties mainly by relying upon third party apps that were built using Reddit’s API. By fixing a price for the API that popular third party developers could not possibly afford, Reddit was essentially shutting down these apps. Moreover, by shutting down these apps, Reddit was ignoring the needs of moderators, arguably their most important users.
In order to remind Reddit of their importance, moderators came together to devise a blackout of unprecedented scale. Subreddits went private for 48 hours. Hopefully, the company would recognize how much they needed their moderators and give in to their demand of reducing the price of API access.
Unfortunately, this objective was not met. Reddit was determined to remain faithful to its business decision and wait out the blackout. Moderators were also unwilling to back down. After the originally planned 48-hour protest period was over, many subreddits remained private. The company then began to antagonize moderators by threatening to remove them and forcing subreddits to reopen.
While some subreddits remain private even today, the blackout largely came to an unsuccessful end. The company was able to force many subreddits back into some form of normalcy, but community sentiment towards management has never been lower. In a post about the blackout, a moderator said, “I believe that Reddit administration has demonstrated an unsurprising but none-the-less disappointing lack of foresight and understanding of how their website operates… I believe [they do] not understand the value that their unpaid moderators bring to the website” (“[Modpost] Reddit Blackout – What’s Happening Next,” 2023). Moderators feel that Reddit’s actions have made it abundantly clear how little the company cares about their users’ perspectives and moderator labor.
This semester, I wanted to understand how the Reddit Blackout affected (1) Reddit as a community nurtured by volunteers and (2) Reddit as a dataset. The following questions guided my work:
How do people use Reddit to seek support?
What does current research say about the struggles of Reddit moderators?
Now that API access is gone, is running a large-scale data analysis about the blackout feasible?
Support Seeking on Reddit
Social support is the receipt of help from others by an individual (Zou 2024). Reddit is a social media platform structured into subject-specific communities (called subreddits) where users can post and interact. This topic-specificity makes Reddit a convenient venue for seeking social support. In fact, it has been praised for hosting certain support-seeking communities, particularly those serving people attempting sobriety (Sowles 2017). Subreddits that support drug recovery are just one of many support-giving communities. Redditors can receive emotional, informational, and tangible social support through the platform (Zou 2024).
Moderator Labor
Volunteer moderators are an integral part of the culture and maintenance of Reddit. However, moderators’ important labor is often underappreciated due to misconceptions regarding what they do. These misconceptions largely stem from two main problems: (1) the lack of visibility around much of moderators’ contributions (Li 2022) and (2) a heightened focus on controversial tasks that they are seldom directly responsible for (Gilbert 2020).
Reddit is designed such that comment removal is highly conspicuous (comments removed by moderators are replaced with the text “[deleted]”), promoting the idea that moderators’ main service is censoring users (Gilbert 2020). However, the majority of comment and post removal is actually performed by bots (Li 2022). So while moderators do find and implement technical workarounds, such as bots, they do not typically perform removals themselves. The misconception that moderators censor users results in community backlash and undue emotional burden on moderators (Gilbert 2020). Moderators also have over 64 other non-removal actions they are responsible for (Li 2022). Unfortunately, a recent study found that approximately 43% of their extensive labor is essentially “invisible” (Li 2022).
The misunderstood and unseen labor of moderators complicates their relationship with Reddit as a company. The value and legitimacy of labor is typically correlated with its level of visibility (Gilbert 2020), so moderators are in a position of disadvantage at the negotiation table with the company (Li 2022). The company’s misconception of the labor of their moderators allows them to neglect the volunteers that keep their platform usable and prioritize investing in what they think will maximize revenue generation. This has been the root cause behind the major “blackouts” that the platform has experienced (Matias 2016).
Data Exploration and Struggles
Given Reddit’s decision to charge for API access, obtaining subreddit data is not as straightforward as it once was. Fortunately, I was able to find a post download tool that enabled us to retrieve data from several support-seeking subreddits.
The subreddit I initially chose to focus on was r/Depression. I analyzed a total of 115,093 r/Depression posts from April 2023 to February 2024. As I was looking through r/Depression posts during the original 48 hour period of the blackout, I realized that no one was mentioning the blackout. The subreddit hadn’t participated in the blackout, but I was still surprised that there were zero references to it. Both during and in the week after the blackout, the most frequently used words were the epitaphs “[removed]” and “[deleted].” I wasn’t sure if this meant that discussion around the blackout had been expunged or that there had never been any discussion around it at all. This made it very difficult to find patterns in posts and sentiments from during the blackout by members of the r/Depression subreddit.
10 Most Frequently Used Words
Frequency
deleted
316
removed
289
feel
40
like
24
want
17
know
16
life
15
tired
8
people
8
depression
7
(Left) Plot of r/Depression posts by day, in which June 12th, the first day of the blackout, is circled in red. It had the most posts of the month. (Right) Top 10 most frequently used words in posts during the blackout. The epitaphs [deleted] and [removed] were most common.
I then chose to redirect my attention to a subreddit that actually participated in the blackout, hoping this would make lack of discussion around the blackout unlikely. I looked at 29,229 r/SocialAnxiety posts from January to December 2023. There were no posts on the subreddit from during the blackout dates. I was not sure if that meant they all got deleted, or if posts from when a subreddit was private are not accessible via the post download tool. Either way, it was clear I needed to adopt a new approach to understand the blackout’s impact.
Planned Quasi-Causal Analysis
After conducting some preliminary exploration of Reddit data from the blackout period, I became interested in determining the effects of the blackout on the culture of supporting-seeking subreddits. Specifically, I want to look at the blackout as an intervention and perform a comparative analysis on the culture of these subreddits before and after the blackout. To do so, I am going to use Regression Discontinuity in Time (RDiT), which we have seen applied successfully in similar work on Wikipedia (Hill 2021).
RDiT is a quasi-causal method that compares regressions before and after an intervention date in order to identify causal effects. The intervention dates will be the initial 48 hour blackout period from June 12, 2023 to June 14, 2023. RDiT is a useful method for the data given that it relies on normalized intervention dates rather than a standard intervention score. RDiT also controls for fluctuations that organically occur over time, ensuring the comparison is strictly in relation to the intervention. This semester, I selected 12 candidate subreddits for analysis.
Selecting Subreddits for Analysis
I want to use data from support-seeking subreddits for my quasi-causal analysis. In particular, I want to analyze support-seeking subreddits across four categories: mental health subreddits that participated in the blackout, mental health subreddits that did not participate in the blackout, non mental health subreddits that participated in the blackout, and non mental health subreddits that did not participate in the blackout. I want to understand whether the intervention had an effect on participating subreddits by looking at how it affected both participating and non participating subreddits. I also want to grasp how the cultures of mental health support-seeking subreddits specifically were impacted by decisions to become private or restricted. After all, these subreddits can be especially critical for people in crises, making their shutdowns potentially more damaging than others’ for consumers of Reddit.
Table of the 12 subreddits selected for the quasi-causal analysis.
Selecting subreddits within the four categories faced three main challenges: they each had to be support-seeking, have around the same number of members as their counterparts, and be available for research and download. Furthermore, each subreddit had to be investigated to determine whether they participated in the blackout or not. Initially, a post on the r/ModCoord subreddit that listed all blackout-participating subreddits was consulted. From here, after manual inspection of member numbers, the following 6 subreddits were selected that participated in the blackout: r/BPD, r/Autism, r/SocialAnxiety (3 mental health subreddits), and r/Confidence, r/LearnMath, and r/MaleHairAdvice (3 support-seeking but not mental health related subreddits). Manual inspection of subreddits by size on the “Top Communities” pages of Reddit yielded 6 more subreddits. These 6 subreddits did not participate in the blackout: r/CPTSD, r/Lonely, r/MentalHealth (3 mental health subreddits), r/FreeFood, r/NeedAFriend, and r/Texts (3 support-seeking but not mental health-related subreddits). Together, these 12 supporting-seeking subreddits form the dataset upon which I will be conducting my quasi-causal analysis.
Closing Remarks
The Reddit blackout remains one of the largest and best documented online protests. Although the disruption appeared to have little impact on Reddit’s business decision, its consequences for the people who rely on Reddit’s communities for social support are unexplored. Next semester, I look forward to better understanding how online collective action changes support-seeking communities long term.
References
Gilbert, S. A. (2020). “I run the world’s largest historical outreach project and it’s on a cesspool of a website.” Moderating a Public Scholarship Site on Reddit: A Case Study of r/AskHistorians. Proceedings of the ACM on Human-Computer Interaction, 4(CSCW1), 1–27. https://doi.org/10.1145/3392822
Hill, B. M., & Shaw, A. (2021). The Hidden Costs of Requiring Accounts: Quasi-Experimental Evidence From Peer Production. Communication Research, 48(6), 771-795. https://doi.org/10.1177/0093650220910345
Li, H., Hecht, B., & Chancellor, S. (2022). All That’s Happening Behind the Scenes: Putting the Spotlight on Volunteer Moderator Labor in Reddit. Proceedings of the International AAAI Conference on Web and Social Media, 16(1), 584-595. https://doi.org/10.1609/icwsm.v16i1.19317
Matias, J.. (2016). Going Dark: Social Factors in Collective Action Against Platform Operators in the Reddit Blackout. 1138-1151. 10.1145/2858036.2858391.
Morrison, S. (2023, June 20). Reddit blackout: What is it and why are subreddits going dark? Vox. https://www.vox.com/technology/2023/6/14/23760738/reddit-blackout-explained-subreddit-apollo-third-party-apps
Peters, J. (2023, June 30). How Reddit crushed the biggest protest in its history. The Verge. https://www.theverge.com/23779477/reddit-protest-blackouts-crushed
Sowles, S. J., Krauss, M. J., Gebremedhn, L., & Cavazos-Rehg, P. A. (2017). “I Feel Like I’ve Hit the Bottom and have no Idea what to Do”: Supportive Social Networking on Reddit for Individuals with a Desire to Quit Cannabis Use. Substance Abuse, 38(4), 477–482. https://doi.org/10.1080/08897077.2017.1354956
Zou, W., Tang, L., Zhou, M., & Zhang, X. (2024). Self-disclosure and received social support among women experiencing infertility on reddit: A natural language processing approach. Computers in Human Behavior, 154, 108159-. https://doi.org/10.1016/j.chb.2024.108159