According to the song, “Getting to know you…. getting to know all about you…” is a lot of fun. But when you go to a new doctor, and fill out a 10-page patient intake form so the doctor can get to know you, it’s not so much fun.
The same has been true for recommender systems. A typical experience for new users is to rate a bunch of items to let the system know their preferences. For example, in the MovieLens film recommender, first-time visitors had to rate 15 movies (see the screen below). This process usually required paging through multiple screens, took over 5 minutes, and discouraged some people so much they dropped out before ever making it to the site home page!
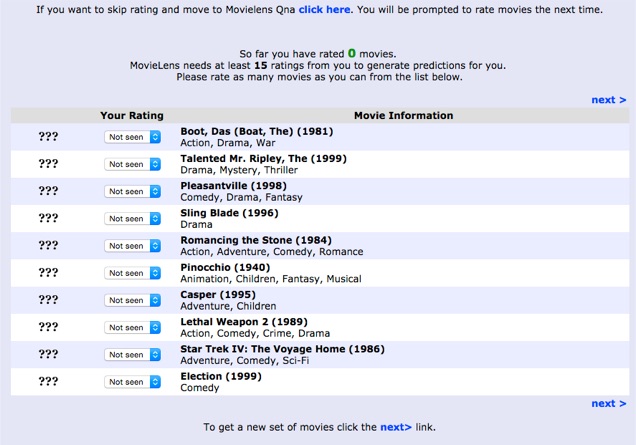
But this is the price you have to pay for personalized treatment — whether from a doctor or film recommender — right?
Well, sort of. Recommender systems researchers call this the “user cold-start problem” and have been working to solve it for years. They have been improving the quality of personalization after the onboarding process, so that users think it worthwhile to go through the process. Researchers have published many papers about how to find the optimal sequence of items (15 movies in MovieLens) to learn a user’s interest, e.g. ordering items by the entropy of ratings, constructing decision trees from items, and so on.
We came up with a new approach to this problem when we redesigned the onboarding process for the new version of MovieLens. Our approach is based on the intuition that users can efficiently train the system by expressing preferences for algorithmically-generated groups of items. A full paper describing this research study will appear in proceedings of CSCW 2015.
When we designed the new version of MovieLens, we were faced with two seemingly contradictory goals: requiring minimal user effort and providing high-quality personalization. Our idea is to ask new users to provide preferences by choosing groups of items that represent their preferences. We operationalized this in MovieLens as groups of movies described by three representative movies and three descriptive tags (see below for a screenshot). This is based on the intuition that expressing preferences for groups of items requires less effort than expressing multiple preferences for individual items. For example, rating “Disney animation” takes less effort than rating “Frozen”, “The Lion King”, and “Bambi” individually. Once a user has expressed a preference for a movie group, we can pretend that user has the typical ratings profile of more experienced users who also prefer that group. In this way, we are able to tie new users into our standard ratings-based personalization framework.
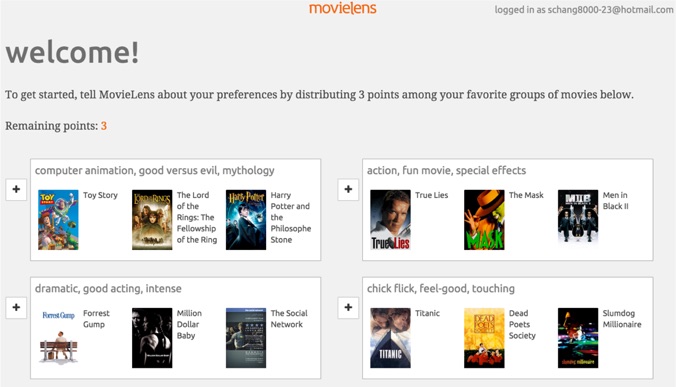
In our published paper, we described several design challenges (and our solutions) raised by our new process:
- generating movie groups using clustering algorithms;
- visualizing the movie groups to users;
- collecting user preferences for movie groups;
- recommending movies based on users’ group preferences.
We evaluated the new process through offline simulation and an online user experiment. We found that the group-based process takes less than half the time of the old “rate 15 movies” process. Better still, we found that the new process provides more useful initial recommendation lists, as judged by the users in our study. The trade-off is slightly reduced prediction accuracy, because we cannot infer user rating bias from preferences on item groups.
Our approach is generalizable to any collaborative filtering-based recommender system. Next time you hear user complaints when building an onboarding process for a recommender system, give our approach a try!
We encourage you to attend our talk at CSCW, read the paper, or try out the new process in MovieLens!